Author: Chris Nickson
Peer reviewers: Sarah Yong
Nuts and Bolts of EBM Part 3
Outcomes matter. They are where the buck stops. They are the proof in the pudding. When someone says ‘show me the money’, what they really want to see are the outcomes.
Outcomes are important for conducting and interpreting research. As we have discussed previously in the Nuts and Bolts of EBM series (see Part 2, Q1,), the PICO format is useful when constructing a research question or when using published research to answer a clinical question… Need I point out that the ‘O’ in PICO, stands for ‘outcomes’?
But wait there is more… Outcomes are also important for assessing the quality of care provided by healthcare services. In the ICU world an important example is the ‘SMR’ or standardised mortality ratio.
That is why, as evidence-based clinicians, we need to know the ‘ins and outs’ of outcome measures.
Q1. What exactly are outcomes or endpoints?
In clinical trials, outcomes and endpoints are the same things. They are the response variables used to compare groups (i.e. the intervention group(s) and the comparison group(s)). A response variable is a particular quantity that we ask a question about in a study, which is influenced by explanatory variables (such as the presence or absence of an intervention). Most trials have several outcomes, some of which are of more interest than the others.
As clinicians, we need to assess the importance of an outcome measure when we read a paper to determine its external validity. Remember, external validity refers to the generalizability of the study to your own patients (see Part 1, Q3).
Whenever we read a paper we should ask ourselves, does this outcome measure really matter?
Then we should look at the effect size (if any) for the outcome of interest and ask ourselves if that really matters too.
Q2. What is the difference between a primary and secondary outcome?
The primary outcome is the pre-specified outcome considered to be of greatest importance to relevant stakeholders (such a patients, policy makers, clinicians, funders… but especially patients!) and is usually the outcome used as part of the trial’s sample size calculation.
Some trials may have more than one primary outcome. However, this is not recommended as it incurs the problems of interpretation associated with multiplicity of analyses (Wikipedia calls this the multiple comparisons problem).
Secondary outcomes are endpoints that are of interest, but for which the trial was not explicitly powered to detect differences in. In most circumstances they should not be used to guide clinical practice but may suggest areas for further research or help explain the result obtained for the primary outcome.
Q3. What are composite outcomes and why are they used?
A composite outcome is a somewhat arbitrary combination of multiple endpoints that are treated as if they are a single endpoint. It typically includes mortality combined with one or more major co-morbidities.
Reasons for using composite outcomes include:
- If there is no clear preference for a primary outcome, or there are multiple important endpoints (a good example would be a neurosurgical trial that uses ‘death and persistent vegetative state’ as a composite endpoint)
- To increase statistical efficiency (ie. increase the power of a trial, by increasing the event rate for the outcome, without needing to increase sample size)
However, there are problems with using composite outcomes:
- Components must be measurable events that can be sensibly be combined together as part of the same disease process
- May include clinician-driven outcomes (e.g. ‘decision to perform revascularization’ combined with mortality and myocardial infarction in cardiology trials) that are amenable to change and may be subjective or more prone to bias
- Components may not all move in the same direction (e.g. mortality may worsen, and less important surrogate endpoints may improve)
- May include a combination of hard clinical endpoints and ‘softer’ endpoints (e.g. biomarker changes such as troponin rises)
- selection of components might be influenced by the interests of trial sponsors and licensing authorities
Given these issues, composite endpoints are best avoided if possible. Ultimately, they are problematic because it is difficult to appropriately assign weightings to the individual endpoint components, which typically vary in importance.
Q4. What are patient-centered outcomes?
Patient-centered outcomes are those that reflect the way a patient “feels, functions and survives” (to quote a CICM exam report!). They are also referred to as patient-orientated outcomes.
For the patient, and thus the clinician, patient-centered outcomes are useful for clinical decision making as they involve things that are actually important to patients. Research that uses patient-centered outcomes forms the basis of ‘patient orientated evidence that matters’ (POEM). This is in stark contrast to disease-orientated evidence (or DOE). One should be wary of disease-orientated evidence because, as Osler said:
“the good physician treats the disease; the great physician treats the patient who has the disease.”
A famous example is the CAST trial. In the 1980s it was known that many patients died from dysrhythmias after myocardial infarction. This it was hypothesised that using an antiarrhythmic drug like flecainide to suppress premature ventricular contractions (PVCs) would help patients. Flecainide proved to be good as suppressing PVCs. However, it was also associated with increased rates of sudden cardiac death and all-cause mortality… patient-centered outcomes that matter!
Examples of patient-orientated outcomes used in critical care trials include:
- Mortality (e.g. ICU, hospital and 90-day)
- Functional status (e.g. at 1 year)
- Health-related quality of life (e.g. SF36 scale)
These outcomes have various pros and cons, of which CICM examiners have in the past thought important, as described in the LITFL CCC entry on ICU Outcomes.
Unfortunately, patient-centered outcomes often pose various problems for researchers:
- they can be difficult to measure
- they may include a subjective component (e.g. the way patients feel)
- they may be contingent (e.g. the benefit of longevity depends on the quality of life associated with it)
- they may have a significant time lag between the intervention and the benefits requiring extensive follow up (e.g. increase in lifespan)
Surrogate outcomes often don’t have these problems, at least not to the same extent.
Q5. What are surrogate outcomes and why are they used?
Surrogate outcomes are biomarkers intended to substitute for a clinical endpoint and expected to predict clinical benefit or harm based on epidemiologic, therapeutic, pathophysiologic, or other scientific evidence. Unfortunately, much of the evidence for clinical interventions is based on surrogate outcomes, rather than outcomes that actually matter to patients.
In some cases surrogate outcomes mutate into actual disease entities (such as hypertension). However, as discussed above, disease-orientated outcomes are not as useful as patient-centered outcomes for clinical decision making.
A reasonable use of surrogate outcomes is in Phase II trials. Here it is important to see if an intervention may have efficacy, before embarking on an appropriately powered Phase III trial using patient-centered outcomes to definitively prove clinical effectiveness. However, when surrogate outcomes are used in research, it is best to use clinical endpoints rather than non-clinical endpoints such as biomarkers. Biomarkers are often difficult to validate and rarely translate into clinically meaningful outcomes.
Useful examples of surrogate clinical endpoints used in ICU research include:
- Hospital-free days to Day 90
- ICU-free days to Day 28
- Ventilator-free days to Day 28
- Cardiovascular support-free days to Day 28
- Renal replacement therapy-free days to Day 28
A good rule of thumb is that, unless validated against a patient-centered outcome, surrogate outcomes should not be used to change clinical practice. Treatment of surrogates outcomes can lead to unintended consequences… particularly if they are used to guide healthcare. Surrogate outcomes may lead to distraction from patient-centered outcomes and may be subject to ‘gaming’ to meet performance indicators (e.g. the ‘4 hour’ rule, ICU readmission rates, and CLABSI rates).
Q6. Why are “[support] free days” preferable to duration or length of stay?
Most effective ICU interventions will have only a small effect on overall mortality. To detect such differences very large sample sizes would be needed to generate enough ‘events’ to adequately power the trial. For this reason, surrogate outcomes such as hospital length of stay or duration of mechanical ventilation are often used.
However, “(support) free days” (e.g. days free of mechanical ventilation while hospitalised) are preferred for a number of reasons:
- they allow trials to have greater power at smaller sample sizes
- death can be reported as ‘zero free days’, thus avoiding the complication of patients who die early having shorter stays in hospital and requiring less mechanical ventilation
- they may provide a surrogate measure of resource utilisation and cost
Thus ‘free days’ are a composite endpoint that combines duration of support for survivors with the ‘hard’ clinical endpoint of mortality. Ideally, duration of support or length-of-stay should also be reported for all patients, for both survivors and non-survivors.
Of course, cost-effectiveness is often a neglected outcome measure in the world of ‘expensive scare medicine’…
Q7. How should the authors of clinical trials describe outcomes?
According to CONSORT, investigators should identify and completely define all pre-specified primary and secondary outcome measures, including how and when they were assessed. The primary outcomes should be explicitly indicated as such in the report of a clinical trial. This prevents any jiggery-pokery going on after a trial has been conducted, otherwise, we may find base lead transmuted into the shiniest gold…
CONSORT also states that available and appropriate outcomes should be reported using previously developed and validated scales or consensus guidelines. This increases the quality of measurement and assists in comparison with similar studies. The use of previously unpublished or unvalidated measurement tools is a common source of bias in trials.
Importantly, if trial outcomes are changed at any stage, this should be reported by the trialists and an explanation provided.
Finally, a clinical endpoint committee may be required as part of the trial to adjudicate on subjective outcome measures and to reduce investigator variability (e.g. in a cardiology trial, how exactly are non-fatal myocardial infarctions diagnosed?)
As stated back at the beginning of this ‘nuts and bolts’ episode, outcomes aren’t just important to researchers, they are are important in the real world too. For this reason, we need to know a bit about ‘Standardised Mortality Ratios’ or SMRs.
Q8. What is the standardised mortality ratio (SMR) and what is it used for?
The Standardised Mortality Ratio (SMR) is the ratio of the observed or actual hospital mortality and the predicted hospital mortality for a specified time period.
As such, it requires an estimate of predicted mortality rate using a scoring system. ANZICS used to use APACHE, but now uses an Australasian-specific prediction tool called ANZROD (see CORE — Severity Score and Risk of Death Calculators).
An SMR value of 1 is considered ‘normal’ or ‘as expected’, whereas >1 is worse than expected and < 1 is better than expected.
SMR is used as a surrogate for good quality of care to allow:
- comparison of different ICUs
- monitor improvements or decline in ICU care over time
A funnel plot is typically used to visually compare different ICUs (the red dot is an example of an outlier with a high SMR):
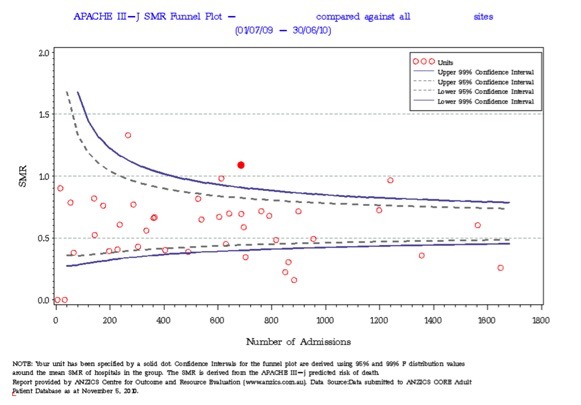
Example from ANZICS CORE (http://www.anzics.com.au/Pages/CORE/About-CORE.aspx)
Note that the whole plot appears shifted below and SMR of 1. This is because the APACHE severity scores were created in the increasingly distant past using non-Australasian populations and over-estimate predicted mortality in modern Australasian ICU patients as a result.
Another useful visualisation is the EWMA graph (exponentially weight moving average graph), which helps show changes in individual unit performance over time:

Example from ANZICS CORE (http://www.anzics.com.au/Pages/CORE/About-CORE.aspx)
Interestingly, the EWMA graph grew out of a need to effectively visualise performance monitoring statistics such as the CUSUM statistic, which is the statistical legacy of the notorious serial killer Dr Harold Shipman (see Shipman’s Statistical Legacy). (Hat tip to Prof Dave Pilcher for that one!)
Q9. What are the advantages and disadvantages of using SMRs for comparisons of ICU performance?
As with everything, there are always pros and cons.
Advantages of using SMRs for comparisons include:
- they are widely used
- they are quantitative
- they are better than a comparison of non-adjusted mortality data
- mortality is a hard endpoint that is clinically meaningful
Disadvantages include:
- acceptable deviations from SMR are not defined, therefore whether a unit significantly deviates from normal is unquantifiable
- needs to be considered in the context of case-mix and calibration (e.g. different ICUs may have different case mixes, and the prediction tool may vary in accuracy with different patient groups, e.g. cardiothoracic surgery versus neurosurgery)
- inconsistencies and inaccuracies associated with data collection and scoring
- missing data limits inclusion of all patients
- original population used to calculate formulae possibly not generalisable
- model used for prediction may be inaccurate
- relies on mortality as a surrogate for quality care
- cost
- ideally samples should be very large
- does not account for post-ICU mortality or morbidity that may be unrelated to ICU care
By the way, if you have a CICM fellowship exam coming up, you might want to think about the various reasons why an ICUs SMR might fall from one year to the next…
References and links
- CONSORT Statement Website [accessed 6 June 2016] (the CONSORT statement is a must read!)
- Nickson CP. Standardised Mortality Ratio (SMR). Lifeinthefastlane.com. 2016 [cited 19 July 2016]. Available from: http://lifeinthefastlane.com/ccc/standardised-mortality-ratio/
- Nickson CP. ICU Outcomes. Lifeinthefastlane.com. 2016 [cited 19 July 2016]. Available from: http://lifeinthefastlane.com/ccc/icu-outcomes/
- Nickson CP. Phases of Clinical Researcg. Lifeinthefastlane.com. 2016 [cited 19 July 2016]. Available from: http://lifeinthefastlane.com/ccc/phases-of-clinical-research/
- Nickson CP. Surrogate Outcomes. Lifeinthefastlane.com. 2016 [cited 19 July 2016]. Available from: http://lifeinthefastlane.com/ccc/surrogate-outcomes/
- Pilcher D, Paul E, Bailey M, Huckson S. The Australian and New Zealand Risk of Death (ANZROD) model: getting mortality prediction right for intensive care units. Critical care and resuscitation : journal of the Australasian Academy of Critical Care Medicine. 16(1):3-4. 2014. [pubmed] [free full text]
- Schoenfeld DA, Bernard GR, ARDS Network. Statistical evaluation of ventilator-free days as an efficacy measure in clinical trials of treatments for acute respiratory distress syndrome. Critical care medicine. 30(8):1772-7. 2002. [pubmed]
- Young P, Hodgson C, Dulhunty J. End points for phase II trials in intensive care: recommendations from the Australian and New Zealand Clinical Trials Group consensus panel meeting. Critical care and resuscitation : journal of the Australasian Academy of Critical Care Medicine. 14(3):211-5. 2012. [pubmed] [free full text]